Kafka functionalities

What is Apache Kafka: An overview of a technology
September 6, 2022
10 mins to read
Research shows companies with big data solutions increase profits by 8%. One popular open-source solution is Apache Kafka which allows organizations to build a robust data streaming platform.
Companies can use Apache Kafka to store and manage real-time data, such as online transactions, website traffic, clicks, etc. This post will discuss what Apache Kafka is, its uses, architecture, benefits, and challenges.
What is Apache Kafka, and what does it do?
Apache Kafka is an open-source distributed low-latency real-time event-streaming system. An event is a data record that indicates a particular activity. For example, purchasing a product online is an event.
Apache Kafka can store, read and analyze several data records. It can do so from several data sources in real-time using multiple servers simultaneously. It enables applications to get event streams to generate real-time insights. For example, organizations can use Kafka to analyse real-time data like click-through rates. It will help to build user activity tracking and understand how consumers react to different call-to-actions (CTAs).
In this article, we’ll talk about:
Why is Apache Kafka so popular?
In today’s data-driven economy, companies must harness the power of high data volumes to remain competitive. They need cost-effective data solutions that can process big data fast with minimal downtime and data loss.
Apache Kafka’s distributed time managing infrastructure lets organizations achieve such a solution. Since it works on multiple nodes, Apache Kafka provides high throughput and low latency for processing complex events. Also, it replicates partitions to distribute data onto other servers. We’ll later explain the concept of partitions in more detail.
This replication allows for high fault tolerance, meaning if one server fails, other servers will become active to provide data. Moreover, the platform’s publish-subscribe messaging system lets organizations power multiple consumer applications in parallel.
Lastly, the distributed system Apache Kafka comes with Kafka Connect. It’s an open-source component that integrates Kafka with external systems. Such systems include databases, file systems, key-value stores, etc.
How does Apache Kafka work?
To understand how Apache Kafka works, we must first understand messaging technologies. A typical message system transfers data from a source to a destination. It comes in two types — point-to-point and publish-subscribe.
A point-to-point messaging system sends data from a source (sender) to a single destination (receiver) at a time. An example of a source can be an order-processing site where the receiver is an order-processing system. And once the receiver reads or consumes the data or message, it removes it from the queue.
But unlike point-to-point and other messaging systems, a publish-subscribe system allows several sources to publish data. Many consumers subscribe to one or many publishers. Also, the messages or data can persist in the messaging queue for a specific time. They will disappear after the time expires. So even if a particular target consumes the message, it will remain in the queue.
Apache Kafka works on the publish-subscribe method. It allows organizations to send and receive data to and from several event-driven applications. A helpful analogy is a television subscription service. The service sends several messages (TV channels) to consumers who subscribe to it.
Furthermore, it divides high-volume data into several pieces (partitions). Each consumer (destination application) subscribes to a partition. It allows for high scalability as several partitions can serve multiple consumers.
Why you should use Apache Kafka?
As discussed, Kafka offers several benefits, such as high speed, persistent storage, and scalability. But let’s look at the benefits more deeply by understanding Kafka’s architecture and functions.
Kafka functionalities

Apache Kafka provides five functionalities through Application Programming Interfaces (APIs) to process streams of events or records in real-time. We already saw the two functions of publication and subscription of messages.
Through the producer API, Apache Kafka allows a event data source to publish or generate events that a destination application can use for several purposes. For instance, an IoT device can publish signals containing information regarding its health, uptime, and security issues.
The consumer API lets us set up applications to consume messages or events for further
processing. For example, a monitoring application can consume the IoT device’s signals to analyze the device’s performance and notify in case of an issue.
Additionally, the streams API allows users to send and receive data in streams from multiple data sources to many destinations.
Kafka’s connector API lets you link multiple subscribers and publishers with other data platforms like BigQuery to drive data search and analytics.
Finally, Apache Kafka offers a storage repository to retain events for later use. The function ensures quick data distribution in multiple availability zones (multiple locations in specific geographic regions), which, for example, is extremely useful for handling aggregated logs.
Architecture and Concepts

Let’s now understand the essential components of Apache Kafka’s architecture. It will further clarify why Kafka is ideal for real-time streaming data.
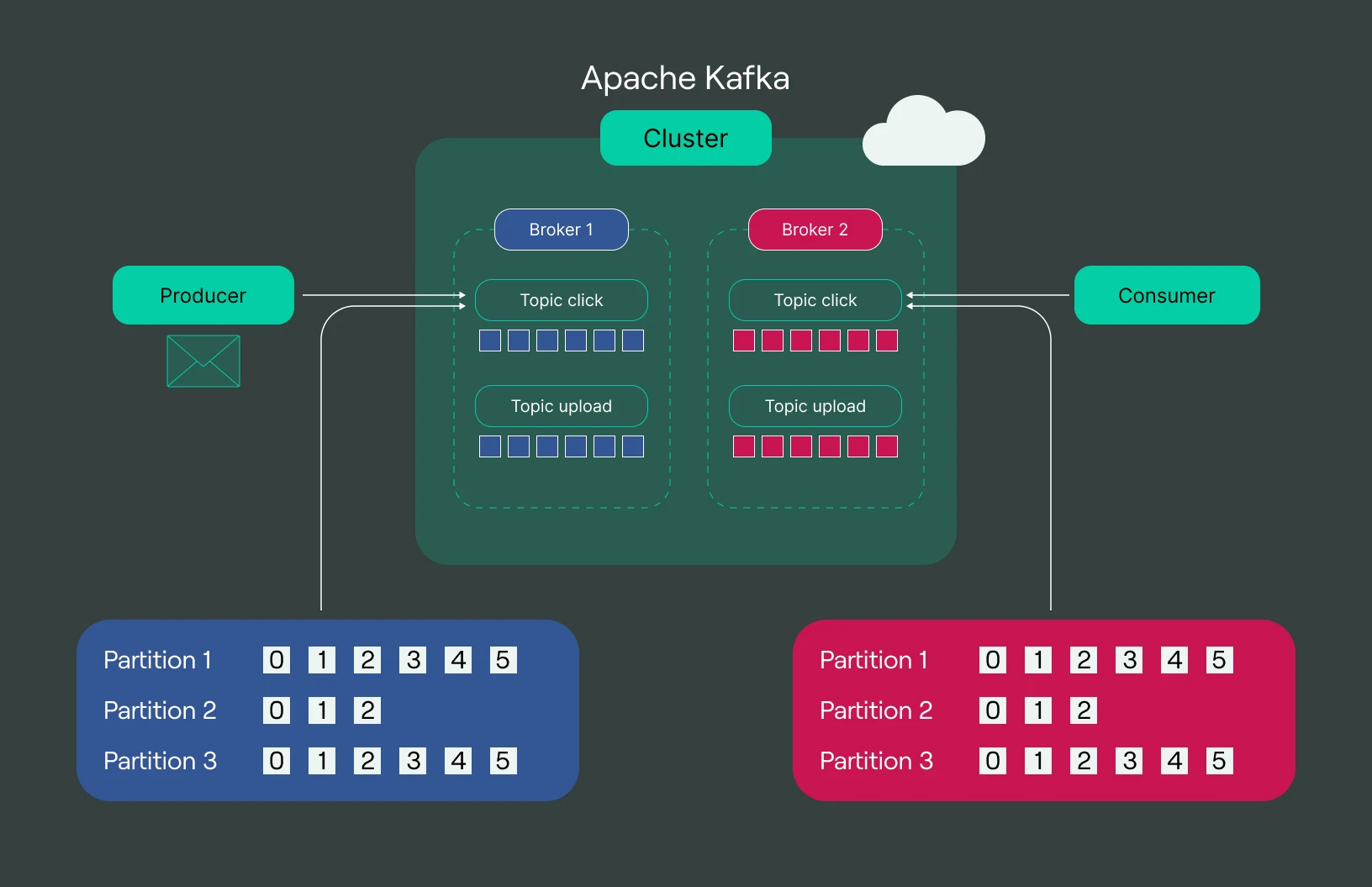
To begin with, producer APIs (data-generating applications) publish and write data on a Kafka cluster (groups of servers). Consumer APIs, as discussed, are applications that receive data from Kafka clusters. As such, Kafka sits in the middle of consumers and producers.
Kafka divides data into topics. A topic is a layer of abstraction that assigns a label to similar streams of records. For example, streaming data from a football match, a cricket match, and a basketball match are three different topics.
Further, Kafka separates a particular topic’s data streams into partitions and stores each in a broker (server). A partition is a data unit containing a sequence of events. Kafka stores a partition as an immutable commit log. Users can’t modify or delete it.
An example of partitions for a football match would be a data stream of different countries — France vs. Argentina, Morocco vs. Portugal, and England vs. Brazil — three different partitions under the football match topic.
Kafka assigns each message/event within a partition a timestamp or an offset according to the order in which it receives a message. For instance, a partition for France vs. Argentina can contain three events. The first can be a goal, the second a foul, and the third a free kick. Kafka will keep logging these events until the match is over.
Consumer applications subscribe to a partition making the system scalable. They can also read records/events in a particular partition in any order. And since Kafka replicates each partition onto several other servers, the architecture is highly fault tolerant.
On top of that, you can configure the expiration time for groups of messages. For example, you can tell Kafka to delete messages older than a day. The practice makes way for new messages to enter the event stream without using a lot of memory.
Lastly, a Zookeeper service manages brokers by coordinating their activities and keeping track of their availability.
Security and Compliance
Apache Kafka lets you configure security settings on producer and consumer applications through Kafka Streams. Kafka Streams is a stream-processing library for developing microservices.
You can enable data encryption to secure communication between Kafka brokers and client applications. Also, client authentication features allow you to specify the clients you want to connect to the Kafka cluster.
Additionally, you can authorize particular clients to have read/write access, letting you restrict specific applications to update Kafka topics.
Kafka performance
Kafka provides a high data stream processing rate due to distributed architecture. And since it divides a data topic into several partitions, data size doesn’t affect Kafka’s performance.
Speed
As mentioned, Apache Kafka works with low latency and high throughput, delivering messages within as low as two milliseconds.
Scalability
The distributed architecture and the publish-subscribe model offer high scalability. Several consumers can subscribe to partitions with less downtime. And replication allows for data processing in multiple availability zones. And, it lets you expand and contract storage per your needs.
How Apache Kafka® Is Used?
Its main functions are centralized collection, log aggregation, real-time processing, secure storage, and transmission of a large number of messages from separate services. A distributed, horizontally scalable platform, it’s usually used for large amounts of unstructured data:
- Large-scale IoT/IIoT systems with a multitude of sensors, controllers, and other end devices.
- Analytics systems: For example, Kafka® is used in IBM and DataSift companies as a collector for monitoring events and a real time tracker of user data stream consumption.
- Financial systems. Bank of America, Nordea, Robinhood, and ING Bank all make use of it.
- Social media: Kafka is part of the infrastructure processing streaming for Twitter, and LinkedIn leverages it to stream data on activity and operational statistics for apps.
- Geo-positioning systems: Foursquare uses it to transmit messages between online and offline systems and integrate monitoring tools into its big data infrastructure built on Hadoop.
- Telecom operators: Verizon, T-Mobile, Deutsche Telekom, and more.
- Online games: For instance, Demonware, a division of Activision Blizzard, processes user logs with it.
Use cases
The simplest example of the use of Apache Kafka® is to collect session logs from clients in streaming mode or logs from physical server files, and then put them somewhere like the Apache Hadoop HDFS file system or ClickHouse®(https://double.cloud/blog/posts/2022/09/what-is-clickhouse-why-column-oriented-dbms-are-important). The service also lets you build a data pipeline to extract business-critical information from raw information using machine learning algorithms.
Read more about Apache Kafka use cases — The Many Use Cases Of Apache Kafka®: When To Use & Not Use It
In general, Apache Kafka is a good choice when you need to:
- Handle large volumes of data streams in real-time or near real-time
- Process and analyze data as it flows through the system
- Integrate multiple data sources and applications
- Provide reliable data transfer between systems
- Scale horizontally and handle high-traffic loads
Who uses Kafka?
Several significant high-tech companies use Kafka to manage data. LinkedIn is the first user and creator of Kafka. It later sold Kafka to Apache.
Spotify, Uber, Tumbler, PayPal, Cisco, and Netflix are among the many renowned names that depend on Apache Kafka for big data processing.
How DoubleCloud help with Managing Apache Kafka?
Although Kafka is a flexible, cost-effective, distributed platform, deployment is still challenging. Deploying Kafka on-premises would require setting up at least a single data center and configuring security protocols and servers. You must also procure adequate physical machines and monitor load to ensure durability.
Additionally, dedicated staff must be present to maintain the system regularly. The team would identify and replace faulty machines with new ones. They would also need to implement updates and resolve issues quickly to minimize downtime.
The process demands a precise skillset and knowledge of the Kafka platform. Due to budgetary constraints, businesses find recruiting the right talent and purchasing the right equipment difficult.
So, getting Kafka as a fully managed service from a third-party vendor is advisable.
DoubleCloud is a viable option that offers Kafka as a managed service. It frees you from conducting routine tasks and lets you focus on creating value from data.
DoubleCloud configures and versions clusters on AWS while encrypting connections for secure communication. You can also benefit from real-time analytics by transferring data to ClickHouse directly.
So try DoubleCloud for free and drive value from real-time big data analytics.
What are Apache Kafka Challenges?
Despite all its benefits, Kafka can be tricky to work with. The most fundamental problem is its inability to store historical data for long. At some point, the messages in a partitioned stream will expire, and data will disappear completely. It also means tuning data retention settings takes a lot of work.
Furthermore, Kafka has limited all-in-one monitoring tools apart from Kafka monitor. Of course, you can get other network monitoring and predictive maintenance tools to keep track of Kafka clusters. But the Kafka monitor is meant for identifying deployment issues. And the network monitor tools only offer standard metrics to track server performance.
Also, if the message size increases, brokers begin to compress them. The compression results in performance loss and reduces speed.
And while partition replication offers high availability, it can cause redundant data copies. They can take up more space and increase storage costs.
Final words
Originally created by LinkedIn, Apache Kafka is now a popular real-time event streaming platform. Significant companies like Uber, Netflix, and Spotify use Kafka to process data and deliver customer value.
Its distributed commit log model and publish-subscribe messaging system offer reliability and flexibility. The data partitioning mechanism makes the platform highly scalable.
However, storing historical data and monitoring its performance takes time and effort. But even so, the platform is the best for building numerous real-time services and data pipelines.
You can also read our comparison guides to help you pick the right tool:

DoubleCloud Managed Service for Apache Kafka
Frequently asked questions (FAQ)
What is Apache Kafka in simple terms?
What is Apache Kafka in simple terms?
Apache Kafka is a distributed streaming platform to handle real-time events. An event is any activity that takes place online.
Is Apache Kafka a database?
Is Apache Kafka a database?
What is Apache Kafka used for?
What is Apache Kafka used for?
How does Kafka relate to real-time analytics?
How does Kafka relate to real-time analytics?
Where does Kafka fit in the Big Data Architecture?
Where does Kafka fit in the Big Data Architecture?
Get started with DoubleCloud



