
Do data types still matter? How column based compression can make data types irrelevant
Written By: Stefan Kaeser, DoubleCloud Solution Architect
I’ve been working with databases for over twenty years now and one of the first things I always do when optimizing performance is to take a look at the used data types.
It may not sound like much if a single number takes up 1,2,4 or 8 bytes of storage, but if you want to store billions of numbers, a factor of 8 will have a big impact on the final space you need… and therefore have a direct impact on your database cost and also speed of queries.
Lately, I had a short discussion with a potential customer.
They were asking if choosing the smallest data type is still important when working with ClickHouse?
Their reasoning behind this was that ClickHouse, as well as other column based DBMS, compress not rows, but single columns, and therefore the compression algorithm should be able to compress the numbers, no matter if we were choosing the smallest possible type, or just use 64-Bit integer all the time.
I instantly said yes, as even in column based DBMS data is not always compressed, but still… it stayed in my mind to evaluate in more detail, if data types still matter in a column based context.
To give away the TL;DR: Yes, data types still matter, but not if you’re only focusing on disk usage.
What are data types?
Before we are going into the details and benchmarking results, I want to give a short recap about what data types are.
Basically data types describe the way to represent data within a DBMS (in our case).
If you want to store for example, the number 57, you have multiple possibilities to store this number in ClickHouse.
You can use some unsigned integer type like UInt8 or UInt64, other possibilities are signed integers like Int16 or Int32.
Maybe not instantly in your focus but also possible would be the String type or to make use of the decimal type.
The main difference between all these types is, how big the numbers can grow and how much space a single number takes up.
UInt8 for example means you can store unsigned integers with a maximum of 2⁸ (256). Each number takes up 8 bits (hence the name UInt8) or 1 byte of space.
Int32 on the other hand allows you to store signed numbers between -2³¹ and 2³¹-1, but each number you store takes up 32 bits or 4 bytes of space.
So if you want to store our example number 57, when storing that number into a Int32 column you are actually storing the 57 in one byte and a lot of additional zeros to fill up the other 3 bytes.
If you want to store the number 57 in a string column, then the single digits would be converted into their ASCII representation and the total length of the string would be added to the storage, hence we would store the information string of length 2 and two bytes representing the digit 5 and the digit 7.
This would make up a total of at least 3 bytes (assuming the length is stored in one byte) used for storing the number 57 in a String field.
So no matter if we add additional zeros to the data or always adding the length of the number to it, when using bigger data types than needed, we are adding redundant data.
This is where compression comes into play.
How does compression help with storing data?
As we’ve seen above, choosing the right data type can have a big impact on the amount of data we need to store on disk, even for a single number.
But what if we don’t want to only store single numbers… but thousands, or millions or even trillions of numbers?
If we want to store them directly, the impact of the data type is exactly the same as if storing a single number.
If one number takes up 3 bytes then one million numbers take up 3 million bytes, and if a single number takes up only 1 byte then a million number takes up only 1 million bytes.
That’s where compression kicks in.
I won’t go into details about how compression works, as this could fill several books (which are already written as well for some parts), but I just want to explain some generics.
Compression tries to remove the amount of redundancy of data.
For example if you have a list of numbers: 5,5,5,5,5,5,5,5,8,8,8,9,1 you could write it in a compressed way: 85,38,9,1
As we can see in that simple example, the big amount of fives could be compressed quite well. The original list took 13 characters (without commas), the new one only 8.
But what about different data types in this regard?
When choosing a non optimal data type, you’re basically adding additional space that a single value would take up.
But as seen before, this space is mostly filled with zeros, so if you have millions of values, you’re actually adding multiple millions of zeros to your data, which means you are adding a lot of redundant data, and compression would remove redundancy.
To go back to our example, let’s say in our list of numbers each number takes up 3 bytes, then the list would look as follows:
005,005,005,005,005,005,005,005,008,008,008,009,001 which would result in 39 characters to store.
But the compressed list would look like this: 8005,3008,009,001 or 16 characters.
So even as the raw data takes up 3 times more space as we are choosing a different data type, the compressed data only takes up 2 times more.
Don’t explain basics to me I want to see real data
As described above, choosing bigger data types than needed mainly adds redundant data to the uncompressed blocks, but when writing data to disk, the redundancy should be eliminated again thanks to compression.
To test this, we use a simple test setup.
We’ll store 100 million rows, containing values between 0 and 100 in different data types.
Then I’ll look at the amount of space these take up on disk, and later on we’ll do some simple queries to see if different data types have an impact on performance.
Test setup
First we define our test table choosing clickhouse default compression and a lot of different data types to store the numbers 0 — 100 in it:
CREATE TABLE dtypes.data_default (
id UInt32,
u8 UInt8,
u16 UInt16,
u32 UInt32,
u64 UInt64,
u256 UInt256,
udec3 Decimal(3,0),
udec30 Decimal(30,0),
ulstr LowCardinality(String),
ustr String,
i8 Int8,
i16 Int16,
i32 Int32,
i64 Int64,
i256 Int256,
idec3 Decimal(3,0),
idec30 Decimal(30,0),
ilstr LowCardinality(String),
istr String
) engine=MergeTree
order by id;
To check if there is a difference when storing signed values, I also added the same columns again but prefixed with an i.
To get the signed values but keep the data distribution, we’ll subtract 50 from the unsigned value, resulting in values from -50 to 50.
Now we’ll fill the table with 100 million rows, generating random numbers between 0 and 100. We explicitly want to store random values, to make sure our dataset itself compresses quite badly, as we only want to see if the redundancy of the data type will be compressed.
INSERT INTO dtypes.data_default
SELECT number, rand() % 100 AS u, u, u, u, u, u, u,
toString(u), toString(u),
rand() % 100 - 50 AS i, i, i, i, i,
i, i, toString(i), toString(i)
FROM numbers(100000000);
I manually ran an OPTIMIZE TABLE data_default FINAL to make sure the data is in as less parts possible, to see the strongest effect of the compression
First result
So how much space does each data type now take up on disk?
Fortunately, ClickHouse collects a lot of statistics in its system tables, so we can easily get the wanted data by running a simple query:
SELECT name, substring(type, 1, 50) as type,
formatReadableSize(data_compressed_bytes) AS comp,
formatReadableSize(data_uncompressed_bytes) AS uncomp,
round(data_uncompressed_bytes / data_compressed_bytes, 2) AS
ratio
FROM system.columns
WHERE database ='dtypes' AND table = 'data_default'
And this is the result:
|
name |
type |
comp |
uncomp |
ratio |
|
id |
UInt32 |
383.12 MiB |
381.47 MiB |
1 |
|
u8 |
UInt8 |
95.78 MiB |
95.37 MiB |
1 |
|
u16 |
UInt16 |
146.84 MiB |
190.73 MiB |
1.3 |
|
u32 |
UInt32 |
279.67 MiB |
381.47 MiB |
1.36 |
|
u64 |
UInt64 |
285.15 MiB |
762.94 MiB |
2.68 |
|
u256 |
UInt256 |
380.01 MiB |
2.98 GiB |
8.03 |
|
udec3 |
Decimal (3, 0) |
279.67 MiB |
381.47 MiB |
1.36 |
|
udec30 |
Decimal (30, 0) |
286.53 MiB |
1.49 GiB |
5.33 |
|
ulstr |
LowCardinality (String) |
95.89 MiB |
95.56 MiB |
1 |
|
ustr |
String |
182.86 MiB |
276.57 MiB |
1.51 |
|
i8 |
Int8 |
95.78 MiB |
95.37 MiB |
1 |
|
i16 |
Int16 |
155.06 MiB |
190.73 MiB |
1.23 |
|
i32 |
Int32 |
281.05 MiB |
381.47 MiB |
1.36 |
|
i64 |
Int64 |
284.83 MiB |
762.94 MiB |
2.68 |
|
i256 |
Int256 |
379.24 MiB |
2.98 GiB |
8.05 |
|
idec3 |
Decimal (3, 0) |
281.05 MiB |
381.47 MiB |
1.36 |
|
idec30 |
Decimal (30, 0) |
285.77 MiB |
1.49 GiB |
5.34 |
|
ilstr |
LowCardinality (String) |
95.89 MiB |
95.56 MiB |
1 |
|
istr |
String |
189.39 MiB |
315.67 MiB |
1.67 |
As you can see, the results resemble the basic assumption we had, that the bigger the data type is, the better the compression ratio becomes, or simply speaking, if a bigger data type in theory takes up double the space than a smaller data type, it doesn’t mean that after compression the data still takes up double the space on disk.
But we also see that choosing the smallest data type possible (UInt8) takes up 95MiB while the biggest one (UInt256) takes 380MiB, so still a factor of 4 for disk usage, which does still matter a lot.
Compression algorithms and codecs
As disk I/O is the most important factor for speed in ClickHouse and disk space being an important factor for cost as well, we could already finish here and conclude that data types still matter and all would be fine.
But ClickHouse has such a wide variety of possibilities for defining columns, using special compression algorithms and codecs for optimizing the compression ratio.
The default algorithm used is LZ4, which is fast and has a good compression ratio overall. But using zstd can lead to a better compression with only a little more impact on the CPU.
There are also some special codecs which can be applied to make data more compressible like T64.
To change a codec in ClickHouse you just need to change the definition of the column you want to apply a different codec on:
CREATE TABLE dtypes.data_t64_zstd (
id UInt32,
u8 UInt8 CODEC(T64, ZSTD),
u16 UInt16 CODEC(T64, ZSTD),
…
The T64 codec
I want to give a short description of the T64 codec, as it can have a strong impact on the compression ratio in the case of using bigger datatypes than needed.
The way it works is that it uses 64 values and writes them in a matrix, then it transposes this matrix and the compression algorithm gets the transposed matrix to compress it.
For better understanding i will demonstrate the logic on 5 values between 0 and 100 and a data type length of 5:
|
0 |
0 |
0 |
1 |
5 |
|
0 |
0 |
0 |
0 |
4 |
|
0 |
0 |
0 |
9 |
1 |
|
0 |
0 |
0 |
5 |
7 |
|
0 |
0 |
0 |
8 |
1 |
Looking at the number it is hard to compress them, but when applying a T64 transformation before, it gets a lot easier to compress:
|
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
0 |
|
1 |
0 |
9 |
5 |
8 |
|
5 |
4 |
1 |
7 |
1 |
So leading zeros in value representation will become zero values, ergo resulting in better compression ratios. Unfortunately T64 cannot be applied to all data types.
Data types and disk space consumption
So finally, let’s see how much really gets stored on the disk, depending on different data types, codes and compression algorithms:
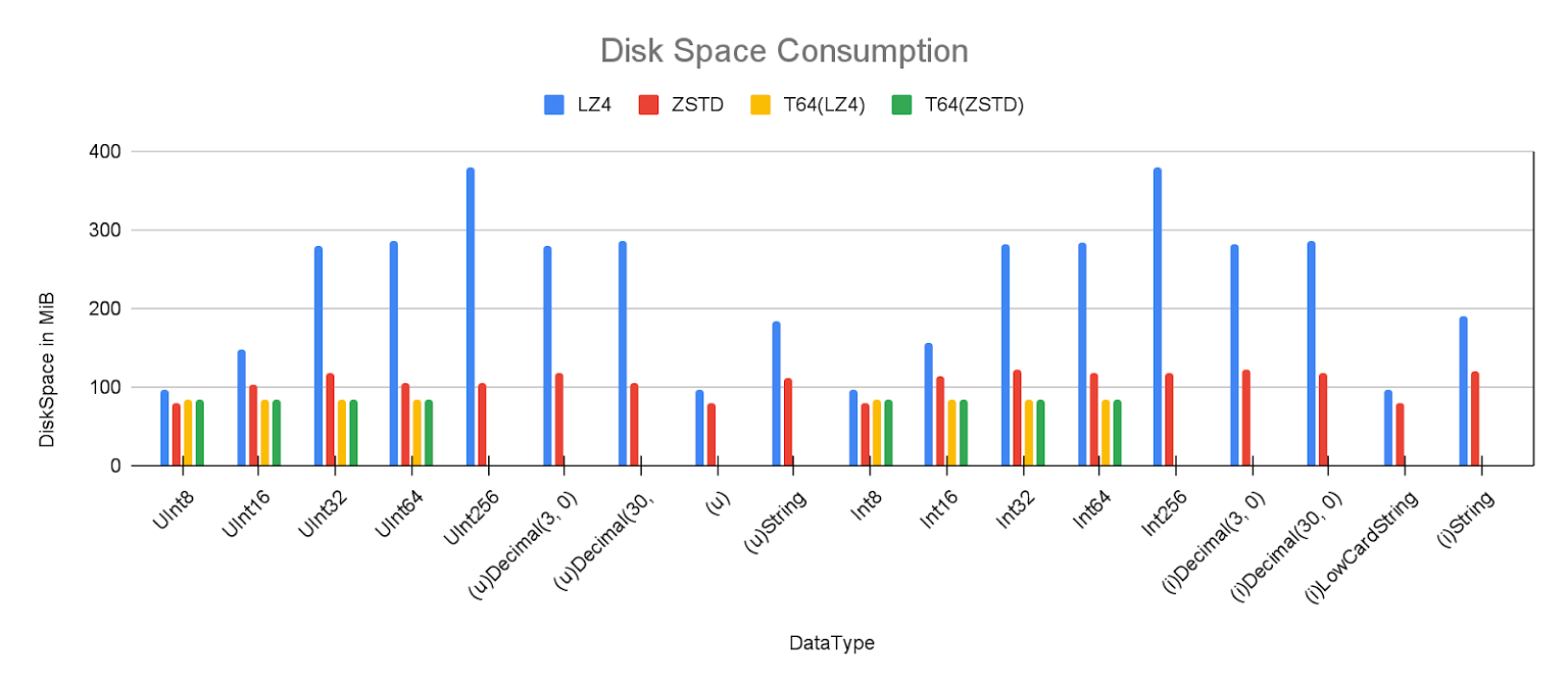
We can see quite the interesting results.
When using the default compression algorithm, the amount of disk space (and therefore cost and I/O performance) varies quite a lot, going from 96MiB for UInt8 up to 380MiB for UInt256.
Using zstd on the other hand leads to a lot smaller variance in sizes, minimum still being around 80MiB for UInt8 but the maximum is only 118MiB for UInt32 (or Decimal3), and even storing the values as string only results in 111MiB for unsigned or 119MiB for the signed ones.
When looking at the results from the T64 transformation, the effect is exactly as wished and the variance there goes from a minimum of 83.8MiB to a maximum of 85.5MiB with nearly no difference between lz4 and zstd.
No disk consumption difference… That means data types really don’t matter anymore?
Whoah! Not so fast with your conclusions there!
Even with the results we saw regarding disk space usage, we’re not at the end yet.
Of course I/O performance is the main bottleneck most of the time, when speaking about general performance of ClickHouse (or other DBMS), but there are more things to consider:
Speed of compression algorithm
If all the algorithms were equally fast, there would only be one algorithm to use, right?
But in real world scenarios, the compression algorithm can make a big difference in speed. Especially when inserting new data… this could have a big impact on how much inserts your application can handle with a given infrastructure.
Memory usage
Even if different data types take up an equal amount of space on your disks because of compression, when using the data within queries you’re not working with compressed data anymore, but ClickHouse has decompressed the data to throw it into the actual calculation logic.
We can already see this in a very simple example.
Let’s say we need to group by our values within different data types, and want to get the average value of the id column:
SELECT u8 AS grp, avg(id)
FROM dtypes.data_default
GROUP BY grp
ORDER BY grp
Grouping as well as sorting has to be done on uncompressed data of course, that means the memory usage of this simple query differs quite a lot, depending on the data type.
(For simplicity, I’ll omit the signed results from now on, as the results are quite redundant to the unsigned).
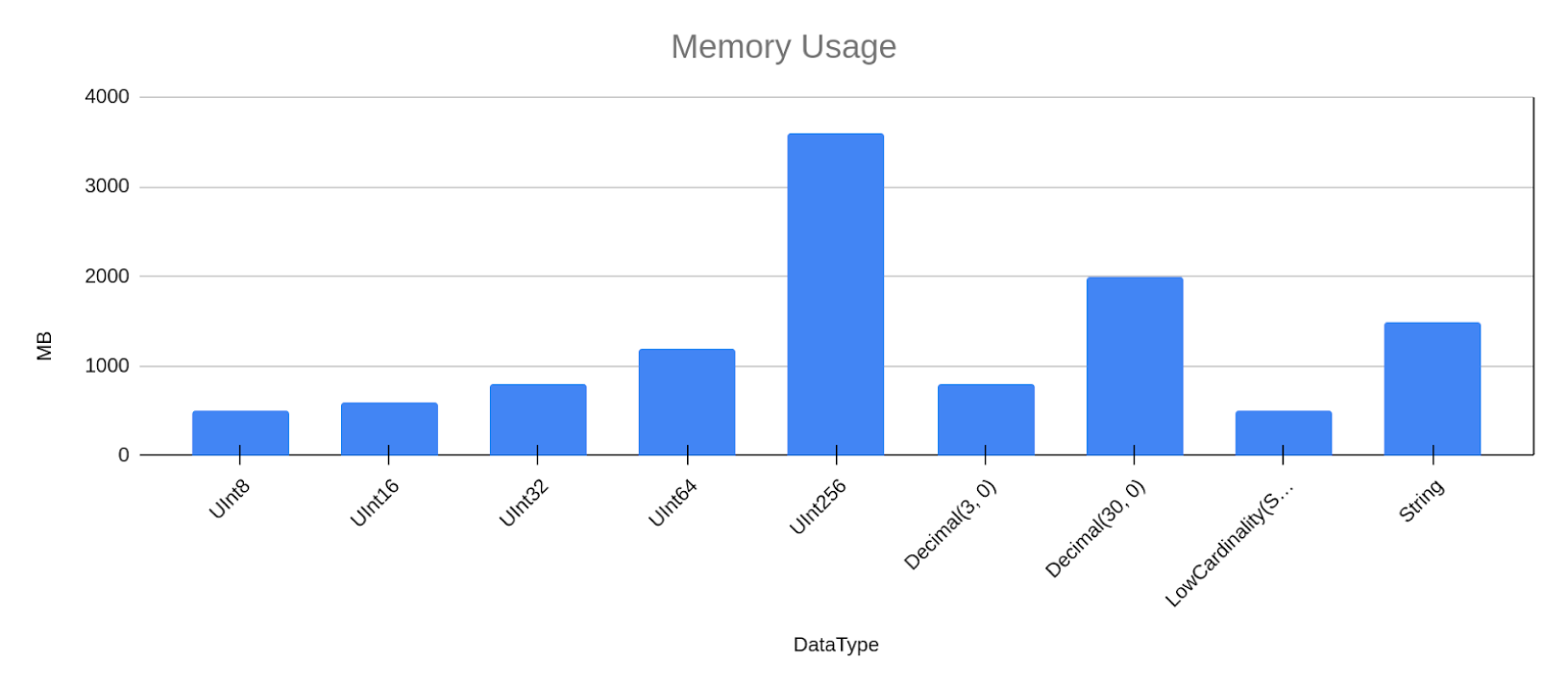
So the data type has a direct impact on the memory usage of queries, which can make a big difference on how many queries you can run in parallel or even if you can get a query to finish in the first place.
Query speed
When working with large amounts of data, query speed is mostly bound on I/O performance. But when data is already in memory because of caching for example, the I/O impact isn’t as important anymore.
Instead other things can take over.
It could make a difference how fast you can copy data within your memory itself, or it could make a difference if some hardware acceleration can be used.
Most cores have no problem handling 32 bit integer values, but handling 256 bit integers might need some special logic within your code. Some very fast sorting algorithms might just work for small data types while others work best only for integer types etc.
And of course, the decompression and transformation of the data also takes some time.
I ran the query from the last section via clickhouse-benchmark on to measure the speed regarding different types and algorithms:
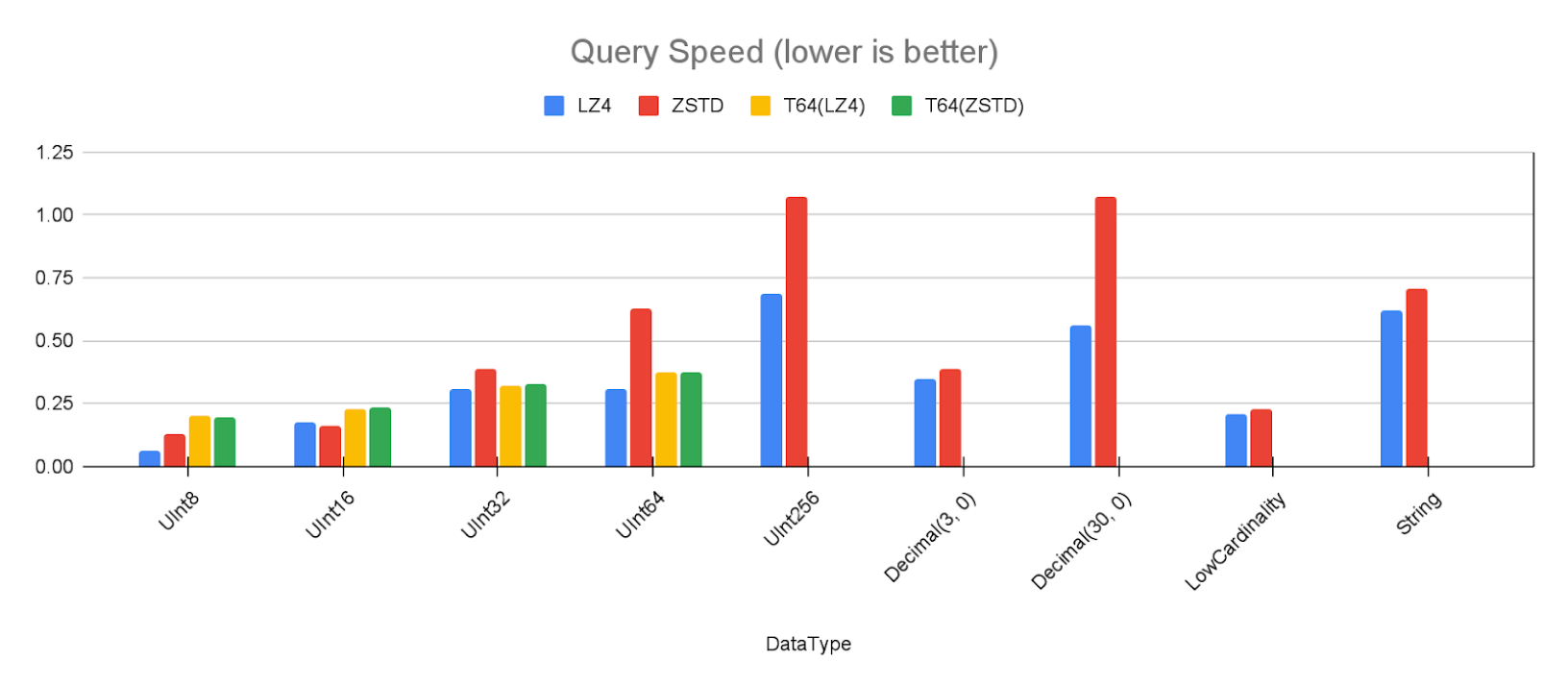
The absolute numbers are not that relevant here, only the relation between the types is interesting. As we can see, regarding query speed, data types can have a big impact on query performance.
Conclusion
So overall our tests and benchmarks confirmed what my gut already thought directly.
Even with such a good compression as columns based DBMS (and especially ClickHouse) provide, data types do still matter quite a lot.
It’s always worth it to check your data and choose the smallest data type needed, to handle all your data.
But regarding disk space alone, the case might be different.
Especially if you want to store a lot of uncleaned or raw data, you might simply just use Strings for that and use ZSTD as compression.
That way, you have the possibility to see when someone accidentally sends incorrect values as well (like user input instead of numbers).
But once you really want to work with your data in the fastest possible way, you should always invest the time to choose the right types.
Your future self will be grateful 🙂.
In this article, we’ll talk about:
- What are data types?
- How does compression help with storing data?
- Don’t explain basics to me I want to see real data
- Test setup
- First result
- Compression algorithms and codecs
- The T64 codec
- Data types and disk space consumption
- No disk consumption difference that means data types really don’t matter anymore
- Speed of compression algorithm
- Memory usage
- Query speed
- Conclusion
Start your trial today



