
What is data pipeline: A comprehensive guide
In the world of big data, businesses are constantly collecting vast amounts of information from multiple sources. This data can include everything from customer interactions and website traffic to social media analytics and supply chain logistics. However, simply collecting this data isn’t enough. Businesses must also be able to process and analyze this data to gain valuable insights.
This is where modern data pipelines come in. It is a series of interconnected components that work together to collect, process, and analyze data. In this guide, we’ll explore the components of a data pipeline, how they work, and why they’re important.
What is data pipeline?
It is a set of processes that extract data from various sources, transform data into a usable format, and load it into a designated storage location. Data pipelines enable the efficient movement of data between systems and ensure that the data is accurate and consistent.
This set of processes can be used for various purposes, including data integration, warehousing, and analysis. Data engineers can use it to automate data processing tasks, freeing up time and resources for other enterprise data and activities.
Different data pipelines are designed with varying complexities and purposes based on their intended use. For instance, Macy’s employs a data streaming pipeline that transfers change data from on-premise databases to Google Cloud. This enables them to deliver a seamless shopping experience for their customers, whether they shop online or in-store.
Similarly, HomeServe utilizes a streaming data pipeline that moves data related to their leak detection device, LeakBot, to Google BigQuery. This data is analyzed by data scientists who continuously refine the machine learning model that powers the LeakBot solution.
In this article, we’ll talk about:
- What is data pipeline?
- Why are data pipelines important?
- Data pipeline architecture
- The components of a data pipeline
- Types of data pipelines
- On-premises vs. cloud data pipeline
- Use cases of data pipelines
- Challenges of building and maintaining data pipelines
- Data pipeline vs. ETL pipeline
- Best practices for building and maintaining data pipelines
- Final words
Why are data pipelines important?
One key benefit is that data pipelines can increase the efficiency and effectiveness of data management. For example, it can automate many tasks in collecting, cleaning, and processing data, reducing the resources and time required to manage data. This, in turn, frees up staff to focus on higher-level tasks, such as analyzing the data and making strategic decisions based on the insights obtained.
Another way this process can increase the efficiency and effectiveness of data management is by improving data quality. By standardizing data formats, cleaning and de-duplicating data, and ensuring that data is properly labeled and categorized, modern data pipelines can help to ensure that data is accurate, consistent, and up-to-date. This, in turn, can help businesses to make more precise and reliable decisions based on their data.
Data pipelines architecture
The design can differ depending on factors like the type of data, its size, and frequency. Therefore, it is essential to choose the right data pipeline architecture that meets the specific needs of a business to achieve its desired objectives. Implementing an appropriate data pipeline architecture ensures efficient and effective data-driven decision-making.
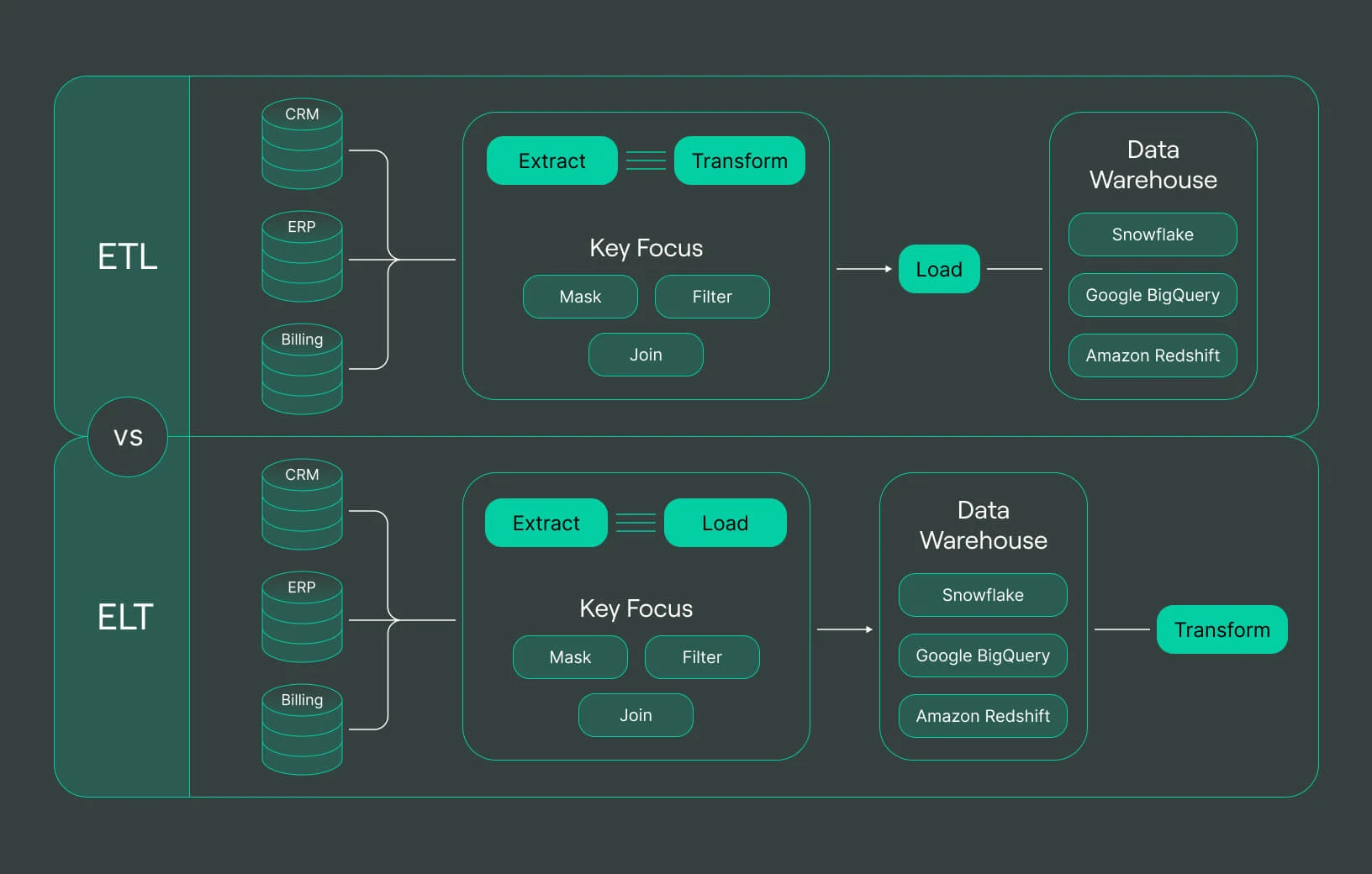

The components of a data pipeline
Let us take a look at each components ofdata pipeline and explain what each components achieve.
Data sources
Data sources are the origins of data collected and processed in a data pipeline. They can be of various types, including structured data from databases, unstructured data from text documents or social media, semi-structured data from JSON or XML files, streaming data pipelines from IoT devices that sensor data, external data from APIs or third-party providers, and more. Examples of data sources include databases like MySQL, MongoDB, APIs like Twitter API, external data providers like weather APIs, and stream processing data sources like Apache Kafka.
Data ingestion
Data ingestion involves collating data from multiple sources and bringing it into the pipeline. It concerns extracting data from data sources and loading data into the pipeline for further processing. Data ingestion may also include validation, enrichment, and transformation to ensure data accuracy and completeness before storing it. Examples of data ingestion techniques include batch processing, where data is collected and processed in large batches periodically, and real-time processing, where data is collected and processed in real time as it arrives.
Data storage
Once the data is ingested, it must be stored in a suitable repository for future processing. Data storage involves organizing and storing the data in databases, data lakes, cloud data warehouses, or cloud storage systems. This stage may also involve indexing, partitioning, and replicating data for efficient data retrieval and processing. Examples of data storage systems include relational databases like MySQL, NoSQL databases like MongoDB, data lakes like Apache Hadoop or Amazon S3, data warehouses like Amazon Redshift or Google BigQuery, and cloud storage systems like Amazon S3 or Microsoft Azure Blob Storage.
Data processing
Transforming data into a more accessible format that can be analyzed and utilized for different purposes is a crucial data management component. This step, known as data processing, is essential to use the available data more. Data processing may involve data cleaning, aggregation, normalization, filtering, enrichment, and more, depending on the specific data requirements and processing goals. Examples of data processing technologies include Apache Spark, Apache Flink, Apache Beam, and data processing frameworks like Hadoop MapReduce or Apache Storm.
Data transformation
This converts data from one format or structure to another within the pipeline. It may involve changing data types, aggregating data, normalizing data, or applying business intelligence to derive new insights. Data transformation is crucial, enabling raw data to be processed and analyzed consistently and meaningfully. Examples of data transformation tools and technologies include Apache NiFi, Talend, and ETL (Extract, Transform, Load) tools like Apache Nifi, Microsoft SQL Server Integration Services, and Oracle Data Integrator.
Data analysis
Data analysis examines, cleans, transforms, and models data to extract useful information, draw conclusions, and support decision-making. Data analysis can be performed using various techniques, including descriptive, diagnostic, predictive, and prescriptive analytics. Examples of data analysis tools and technologies include Python libraries like Pandas, NumPy, and scikit-learn, data visualization tools like Tableau, and machine learning frameworks like TensorFlow and PyTorch.
Data delivery
Data delivery is the process of delivering processed and analyzed data to the target system or application for further processing or consumption. It involves transferring data from the data pipeline to the intended destination, which could be a database, a data warehouse, a reporting tool, a dashboard, or any other system or application that requires the data. Data delivery may involve data transformation, loading, and integration to ensure the data is in the right format and structure for the target system. Examples of data delivery methods include APIs, data connectors, data integration tools, and data loading mechanisms.
Types of data pipelines
There are different types of modern data pipelines based on the processing requirements and characteristics of the data. Let’s explore the three common types:
Batch processing
Batch processing is where data is collected, processed, and analyzed in large batches at scheduled intervals. Data is accumulated over time and then processed in batches. Batch processing is typically used when real-time processing is not required, and data can be processed in large volumes simultaneously.
Batch processing efficiently handles large datasets and performs complex data transformations or data analytics tasks. Examples of batch processing technologies include Apache Spark, Apache Hadoop, and batch ETL tools like Apache Nifi, Talend, and Microsoft SQL Server Integration Services.
Real-time processing
Real-time processing is where data is collected, processed, and analyzed in real-time as it arrives. Data is processed and analyzed as it streams into the system, enabling real-time insights and actions. Real-time processing is typically used when immediate data processing and analysis are required, such as monitoring applications, fraud detection, recommendation systems, or IoT applications.
Real-time processing allows for faster decision-making and rapid response to changing data conditions. Examples of real-time processing technologies include Apache Kafka, Apache Flink, Apache Storm, and real-time ETL tools like Apache Nifi and Google Cloud Dataflow.
Hybrid processing
Hybrid processing combines both batch processing and real-time processing approaches. It allows processing data in batch and real-time modes based on the data characteristics and processing requirements.
Hybrid processing is used when a pipeline needs to handle large volumes of data that can be processed in batches and real-time data that requires immediate processing and analysis. Hybrid processing provides the flexibility to choose between batch and real-time processing based on specific data processing needs. Examples of hybrid processing technologies include Apache Spark, Apache Flink, and hybrid ETL tools like Apache Nifi.
On-premises vs. Cloud data pipelines
Modern data pipelines can be built either on-premises or in the cloud. On-premises data pipelines are built within an organization’s data center. In contrast, a cloud is built on a cloud platform such as Microsoft Azure, Google Cloud Platform (GCP), or Amazon Web Services (AWS). On-premises require an organization to purchase and maintain the hardware and software needed to build and run the pipeline while the cloud provider manages the cloud.
Organizations may use on-premises data pipelines when strict security or compliance requirements prevent them from storing data in the cloud. However, on-premises pipelines can be expensive to build and maintain, as they require significant upfront investments in hardware and software. Cloud data pipelines, conversely, can be more cost-effective as they eliminate the need for hardware purchases and reduce maintenance costs.
Use cases of data pipelines
Data pipeline can be used in various industries and use cases. One example is retail, where pipelines can collect and analyze customer data to improve marketing strategies and customer experiences. In healthcare, this processes can be used to collect and analyze patient data to improve medical research and treatment outcomes.
Another use case is in the financial industry, where they can be used to analyze market data and make more informed investment decisions. This set of processes can also be used in manufacturing to monitor equipment performance and identify potential issues before they become major problems.
Challenges of building and maintaining data pipelines
Building and maintaining modern data pipelines can present several challenges. The most common challenges include data quality issues, technical complexity, scalability, and security concerns.
Data quality issues
Data quality is critical, as poor data quality can lead to inaccurate analysis and decision-making. To ensure consistent data quality, organizations should establish data quality checks and validation rules to catch errors and inconsistencies in data. Additionally, data cleansing techniques such as deduplication, normalization, and data enrichment can be used to improve data quality.
Technical complexity
Building and maintaining pipelines can be technically complex, requiring expertise in various areas, including data modeling, integration, and analysis. Organizations should consider partnering with a team of experts or investing in training to ensure they have the necessary skills to build and maintain their pipeline.
Scalability
Scalability is an important consideration when building a pipeline, as organizations need to be able to handle increasing amounts of data as their needs grow. To ensure scalability, organizations should design their data pipelines with scalability in mind, using distributed systems and cloud technologies that can handle large data volumes.
Security
Data security is a critical consideration when building and maintaining a data stream. Organizations must ensure their data flow is safe from threats like hacking or data breaches. Organizations should implement security protocols such as access controls, user authentication, and data encryption to ensure data security.

DoubleCloud Managed Service for Apache Kafka'
Data pipeline vs. ETL pipeline
A data pipeline and an ETL (Extract, Transform, Load) pipeline are similar in that they both involve moving and processing data. However, the main difference is that the former is designed to handle large volumes of real-time data, while the latter handles smaller batches of data on a scheduled basis. Modern data pipelines are used when organizations need to collect and analyze data in real-time, while ETL pipelines are used when organizations need to process data from multiple sources regularly.
Best practices for building and maintaining data pipelines
Data flow/pipelines are an essential component of modern data-driven organizations. To ensure that your pipeline is effective, reliable, and scalable, it is important to follow best practices when building and maintaining it. Here are some best practices to consider:
Establish clear goals
Before building a data pipeline, it is essential to establish clear goals and objectives. This helps ensure the pipeline aligns with the business’s needs and can deliver the expected outcomes. To set clear goals, consider defining the use cases, data sources, data types, and stakeholders' requirements.
Define a data governance strategy
Data governance is critical to ensuring the quality, security, and privacy of the data being processed by the pipeline. A data governance strategy defines the policies, procedures, and standards for managing data throughout its lifecycle. It is essential to have a data governance strategy in place to ensure that the data pipeline operates within the boundaries of legal and ethical constraints.
Choose the right technology stack
Choosing the right technology stack is essential to ensure the data pipeline can handle the volume, variety, and velocity of data being processed. The technology stack should be selected based on the use case, data sources, and data types. It is also vital to consider the technology stack’s scalability, flexibility, and maintainability.
Implement testing and monitoring processes
Testing and monitoring are essential to ensure the data pipeline performs as expected. Automated testing and monitoring processes are vital to detect and resolve issues quickly. Testing and monitoring should cover all data pipeline stages, including data ingestion, storage, processing, transformation, and delivery.
Foster collaboration between data teams and business stakeholders
Collaboration between data teams and business stakeholders is critical to ensure the data pipeline aligns with the business’s needs and objectives. It is important to make clear communication channels, define roles and responsibilities, and facilitate knowledge sharing to foster collaboration between these groups.
Final words
In the contemporary age of data-driven society, it is indispensable for establishments to have data pipelines that enable them to manage and scrutinize extensive quantities of data efficiently. Data pipelines are an amalgamation of interrelated operations that extract, modify, and store information from diverse origins to a designated repository.
The constituents of a data pipeline include information sources, ingestion, storage, processing, and transformation. By employing an appropriate data pipeline framework, companies can boost the productivity and efficiency of their data management system, resulting in improved data worth and more exact and trustworthy decision-making.
Ultimately, a meticulously designed data pipeline can facilitate enterprises to procure valuable insights and keep up with their rivals in the respective sectors.
EtLT: The Tech That’s Transforming Data Processing
What Is EtLT?
Frequently asked questions (FAQ)
What is data pipeline in simple terms?
What is data pipeline in simple terms?
A data pipeline is a system that enables the automated, efficient, and reliable movement of data from one place to another. It involves a series of processes that extract data from multiple sources, transform it into a usable format, and then store data in a way that makes it easy to analyze and use.
How does a data pipeline work?
How does a data pipeline work?
Is data pipeline the same as ETL?
Is data pipeline the same as ETL?
What are the key components of a data pipeline?
What are the key components of a data pipeline?
Start your trial today



