
Native S3 connector vs. Airbyte S3 connector
Written by: Eraldo Jaku, DoubleCloud Senior Backend Engineer.
Some time ago, when launching our DoubleCloud project, we developed the Data Transfer service. Initially, we wrote some of the connectors ourselves for internal use, and adapted others from open-source resources. These open-source connectors were valued for their diversity, and helped people find solutions for their specific needs. In particular, the Airbyte S3 connector worked efficiently for small amounts of data (about several hundred megabytes) and for serving small clients, especially when it involved transferring several hundred megabytes of data several times a day.
However, we encountered performance issues when a client with a larger volume of data (several hundred gigabytes per day) approached us. Our service faced limitations in its performance, and a detailed analysis revealed two main issues:
-
Our connector, written in Python, serialized all read data into the JSON format, creating a bottleneck in performance.
-
The connector did not support parallel reading of multiple files, as all serialization went through a single channel.
We tried to improve the performance of the connector in various ways, but without success. The first problem could have been solved by rewriting the code from Python to C++, but the second issue was due to the architecture design of the Airbyte connector and required a more radical approach.
Considering that our own connectors were already working successfully and had built-in support for parallelism both between and within logical tables, we decided to develop our own high-performance connector. We chose to create this connector using our own technologies, employing the faster programming language Golang, and ensuring the ability to read and write data in parallel both within and between files.
Initial analysis of the Airbyte connector
-
4 parquet files ~50MB each
-
12671164 rows of data
-
Transfer time 1h 18m 57s
To put these numbers into perspective, if we take the values from this initial use case we can derive that each minute we process 2.3 MB of data. So for 1 GB of data we would have an estimated run time of 6h 36m. For 1 TB of data the run time becomes a whopping ~ 278 Days.
This would be unfortunately too slow for most of our use cases so we needed something more performant.
Our native S3 connector requirements
The new native S3 Connector offers the possibility of reading objects of different formats from an S3 bucket, each with its own peculiarities:
-
Parquet format
-
CSV format
-
JSON Lines format
For all formats, the connector can be used in both snapshots and replication transfers.
Snapshots
We follow a similar approach in all three format readers for snapshotting with the only differences boiling down to parsing different formats.
The reading from S3 is done concurrently on an object basis (multiple objects read concurrently) and the workload can also be split to different workers for parallelization. Each object is read and processed in a chunked approach in all three readers, only differing for gzipped objects (more on this down below).
Automatic schema deduction functionality was built into all three of the readers. In the case of no table schema being provided, an ad hoc one will be deduced from a sample portion of the data.
Disclaimer: Depending on the objects’ file format, this deduction can be more or less precise, with parquet objects featuring more data type precision in the deduction and JSON Line and CSV featuring less precision in the data types. This is due to format specifications and ambiguity in some data types in CSV and JSON Line, e.g., no clear way to identify if the value 32 is an int8, int32, int64, uint8, uint32 and so on.
Replication
For replication, the S3 connector currently offers two different approaches:
-
Polling
-
SQS message based replication
Polling
The polling mechanism is a simple and straight-forward solution for detecting and replication new files from an S3 bucket. To do this, on each run we fetch the full list of objects from the S3 bucket, sorted by the lastModified timestamp and start processing each object found. Each replication run we store the last processed object ID so that we only need to process the newly created objects on the next run.
Disclaimer: As you can imagine from this brief description, this process of fetching the full list of objects on each run can lead to slow iteration cycles for buckets with a high number of objects. For this purpose we implemented a different approach for replications with such parameters.
SQS message replication
An S3 bucket can be configured to send ObjectCreation events on each new object being uploaded to an SQS queue. For more information on how you can create such a configuration in Terraform, take a look at our end-to-end Observability example on Github, where we create an S3 bucket and configure it to push ObjectCreation events to an SQS queue on each time new NLB access logs are uploaded to the bucket.
In our replication process, we then query the messages from this configured queue and process the object mentioned in the message.
Once an object is fully processed we then proceed to delete the SQS message so that only the messages to be processed remain in the queue.
This drastically improves the replication cycle performance since only unprocessed messages in the SQS queue need to be read each iteration.
Gzip format objects
The native connector comes with a built-in functionality for correctly handling gzipped objects in an S3 bucket. To do so, the object in question is downloaded into memory and processed directly from there. Gizipped objects are automatically detected and no additional configuration from a user is needed to cover such cases.
Parquet
The Parquet reader is built with performance in mind and uses parquet-go for parquet file manipulation under the hood.
As mentioned before the reader can deduce a schema from the sample data.
The read data types are then mapped as can be seen below to our internal data types.
Parquet data type mappings
|
Parquet type |
Internal data type |
|
INT64 |
int64 |
|
INT32 |
int32 |
|
INT16 |
int16 |
|
INT8 |
int8 |
|
UINT64 |
uint64 |
|
UINT32 |
uint32 |
|
UINT16 |
uint16 |
|
UINT8 |
uint8 |
|
FLOAT |
float32 |
|
DOUBLE |
float64 |
|
BYTE_ARRAY, FIXED_LEN_BYTE_ARRAY |
bytes |
|
STRING, INT96 |
string |
|
BOOLEAN |
boolean |
|
TIMESTAMP |
timestamp |
JSON Lines data type mapping
|
JSON lines type |
Internal data type |
|
number |
float64 |
|
string |
string |
|
object, array |
any |
|
timestamp |
timestamp |
|
boolean |
boolean |
Additionally, we have two mappings we use for our system columns (in case they are configured to be appended in the transfer).
|
Additional type |
Internal data type |
|
uint64 |
uint64 |
|
utf8 |
string |
CSV data type mapping
Since CSV does not offer any particular data types other than strings of values, we introduced a fictive mapping table in place so that all possible internal data types can be parsed from a CSV file. From these data types, only 4 (string, boolean, float64 and any) are deduced if no schema is provided by the user.
|
CSV type |
Internal data type |
|
int64 |
int64 |
|
int32 |
int32 |
|
int16 |
int16 |
|
int8 |
int8 |
|
uint64 |
uint64 |
|
uint32 |
uint32 |
|
uint16 |
uint16 |
|
uint8 |
uint8 |
|
float |
float32 |
|
double |
float64 |
|
string |
bytes |
|
utf8 |
string |
|
any |
any |
|
date |
date |
|
datetime |
datetime |
|
timestamp |
timestamp |
|
interval |
interval |
Benchmark Airbyte vs Native S3 connector
This benchmark involved using the native S3 connector and the Airbyte S3 connector as sources in a transfer to a ClickHouse target. Both sources read from the same AWS bucket and file. The target for both sources was the same ClickHouse DB.
We tried to configure both sources as similarly as possible. Both sources read/parsed a parquet file. Batch size was in both sources 128.
The Bucket:
For this benchmark we used 3 different file sizes and compositions. We used for one transfer a single 47.1MB parquet file named yellow_tripdata_2022-07.parquet .
For the second transfer, we used 5 parquet files with a total size of 232.7 MB
-
yellow_tripdata_2022-01.parquet 36.4 MB
-
yellow_tripdata_2022-02.parquet 43.5 MB
-
yellow_tripdata_2022-03.parquet 53.1 MB
-
yellow_tripdata_2022-04.parquet 52.7 MB
-
yellow_tripdata_2022-05.parquet 47.1 MB
And for the third transfer we used a large 1 GB parquet file named sample.parquet.
The same bucket was used for both the Native and the Airbyte S3 connector. The bucket was stored on AWS.
DoubleCloud’s no-code ELT tool: Data Transfer
A cloud agnostic service for aggregating, collecting, and migrating data from various sources.
The ClickHouse target:
We used a managed ClickHouse cluster with the following specs:
X86 s1-c2-m4 2 Cores, 4GB RAM, 32 GB SSD storage,
Replicas: 1 ,
Shards: 1, Version 23.8 LTS
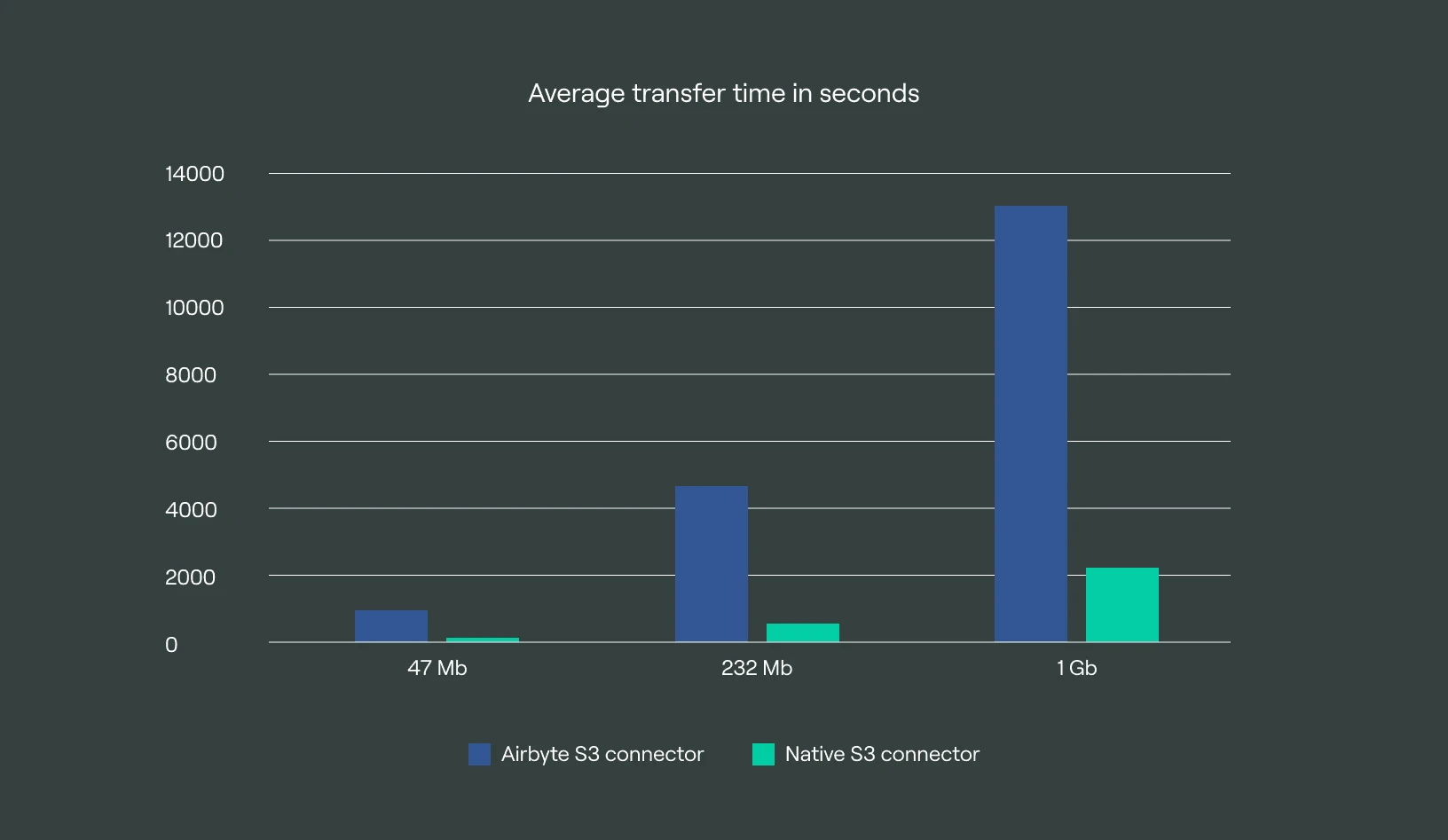
Results
The native S3 connector outperformed the Airbyte S3 connector by a factor of:
-
7.22x in the single file transfer.
-
8.24x in the multi file transfer.
-
5.85x in the large file transfer.
Single file Transfer with Airbyte S3 connector:
3 Total runs were performed with an average transfer time of 932s.
Stats:
Run 1:
Transfer start: 2023-09-21 11:32:59.700604
Transfer finish: 2023-09-21 11:48:24.699727
Total duration: 925s
Run 2:
Transfer start: 2023-09-22 11:27:21.353747
Transfer finish: 2023-09-22 11:43:20.110288
Total duration: 959s
Run3:
Transfer start: 2023-09-22 11:55:43.808376
Transfer finish: 2023-09-22 12:10:55.910761
Total duration: 912s
Average transfer time: 932s
Final row count: 3174394
File Size: 47.1 MB
Single file Transfer with Native S3 connector:
3 Total runs were performed with an average transfer time of 129s.
Stats:
Run 1:
Transfer start: 2023-09-21 12:05:59.494597
Transfer finish: 2023-09-21 12:08:05.364122
Total duration: 126s
Run 2:
Transfer start: 2023-09-22 11:27:15.781086
Transfer finish: 2023-09-22 11:29:25.135816
Total duration: 130s
Run 3:
Transfer start: 2023-09-22 11:33:23.563433
Transfer finish: 2023-09-22 11:35:34.477263
Total duration: 131s
Average transfer time: 129s
Final row count: 3174394
File Size: 47.1 MB
Multi-file Transfer with Airbyte S3 connector:
3 Total runs were performed with an average transfer time of 4631s.
Stats:
Run 1:
Transfer start: 2023-09-28 07:43:37.158262
Transfer finish: 2023-09-28 09:05:05.087941
Total duration: 4888s
Run 2:
Transfer start: 2023-09-28 09:28:02.368615
Transfer finish: 2023-09-28 10:42:37.751094
Total duration: 4475s
Run 3:
Transfer start: 2023-09-28 11:03:45.742239
Transfer finish: 2023-09-28 12:19:14.867215
Total duration: 4529s
Average transfer time: 4631s
Final row count: 15845558
Files Size: 232.7 MB
Multi file Transfer with Native S3 connector:
3 Total runs were performed with an average transfer time of 562s.
Stats:
Run 1:
Transfer start: 2023-09-28 07:46:53.427883
Transfer finish: 2023-09-28 07:56:17.097356
Total duration: 564s
Run 2:
Transfer start: 2023-09-28 08:08:27.314499
Transfer finish: 2023-09-28 08:17:47.248286
Total duration: 560s
Run 3:
Transfer start: 2023-09-28 08:25:12.514422
Transfer finish: 2023-09-28 08:34:34.401387
Total duration: 562s
Average transfer time: 562s
Final row count: 15845558
Files Size: 232.7 MB
Large file Transfer with Airbyte S3 connector:
3 Total runs weere performed with an average transfer time of 12990s.
Stats:
Run 1:
Transfer start: 2023-09-28 14:55:43.767675
Transfer finish: 2023-09-28 18:32:23.225131
Total duration: 13000s
Run 2:
Transfer start: 2023-09-29 06:49:30.979583
Transfer finish: 2023-09-29 10:30:05.232716
Total duration: 13234s
Run 3:
Transfer start: 2023-09-29 10:33:39.325142
Transfer finish: 2023-09-29 14:05:57.273409
Total duration: 12738s
Average transfer time: 12990s
Final row count: 60000000
File Size: 1 GB
Large file Transfer with Native S3 connector:
3 Total runs were performed with an average transfer time of 2219s.
Stats:
Run 1:Transfer start: 2023-09-28 14:55:45.872607
Transfer finish: 2023-09-28 15:32:43.741413
Total duration: 2218s
Run 2:
Transfer start: 2023-09-29 06:49:22.173932
Transfer finish: 2023-09-29 07:26:31.372277
Total duration: 2229s
Run 3:
Transfer start: 2023-09-29 07:35:54.074475
Transfer finish: 2023-09-29 08:12:43.321723
Total duration: 2209s
Average transfer time: 2219s
Final row count: 60000000
File Size: 1 GB

DoubleCloud Managed Service for ClickHouse
An open-source, managed ClickHouse DBMS service for building real-time analytics data solutions. Don’t take two days to set up a new data cluster. Do it with us in five minutes.
Conclusion
To summarize:
-
We now have our own custom S3 connector covering similar use-cases as done previously by the airbyte connector.
-
We achieved a significant improvement in the performance of the S3 connector (6-9x faster) when compared to the Airbyte connector.
-
We implemented different approaches to handle replication from an S3 source.
Get started with DoubleCloud



